前言
想象一下,走进一个超级图书馆。这里每本书的内容都有精准标注。书架之间藏着无数关联通道。知识图谱就如同这样一个数字化智能图书馆。它能把分散的信息点编织成知识网络。能让机器“理解”世界。在2025年的今天。这项技术已深入渗透到搜索引擎、智能客服、医疗诊断等各个领域。成了人工智能的基础设施。
知识图谱的核心架构
构建知识图谱如同建造城市,需要清晰的规划蓝图。底层是由<>三元组由(实体-关系-实体)构成的知识单元,就如同城市里的建筑地基。中层是本体建模,它相当于城市规划方案。它能定义各类实体(比如人物、地点)之间的逻辑关系。最上层是应用接口,这好比城市交通网络。它能让不同系统调用这些结构化知识。
以医疗领域来说,把“阿司匹林”“心血管疾病”“血小板聚集”等概念,通过“治疗”“抑制”等关系连接起来。这时就形成了能进行推理的医学知识网络。这种表达方式具有结构化的特点。它比传统数据库用表格存储,更能体现现实世界的复杂关联。
数据获取与知识抽取
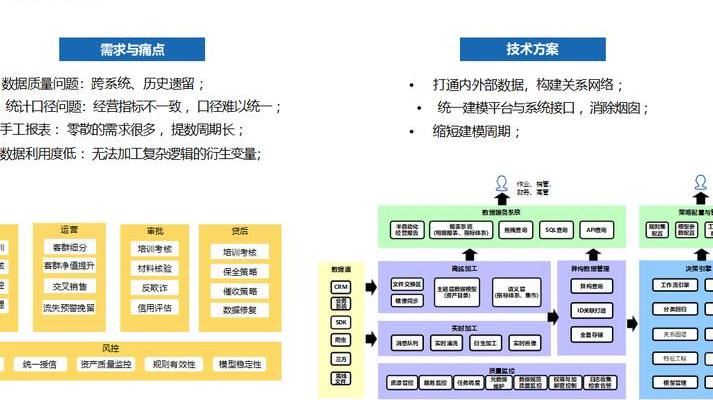
构建知识图谱,第一步是采集原材料。结构化数据就像现成的砖块,能直接从数据库导入。半结构化数据类似预制件,得从HTML表格、Excel中解析。非结构化数据是原始矿石,要借助NLP技术从文本里挖掘实体和关系。到2025年,主流的BERT、GPT等预训练模型,让机器理解自然语言的准确率提高了40%以上。
某电商平台实践表明,借助知识图谱自动抽取商品参数关系,效率比人工标注提升了200倍。不过要留意数据源的质量控制。这就如同米其林餐厅必须严格挑选食材一样。低质量数据会产生“知识污染”。进而致使后续推理出现错误。
知识融合与质量校验
不同渠道来的知识如同方言,得统一“普通话”标准。实体对齐技术要处理“马云”和“阿里巴巴创始人”是同一对象的问题。关系冲突检测要判定“番茄是水果还是蔬菜”这类争议。2025年最新的图神经网络技术,可把实体相似度判断准确率提高到92%。
金融风控领域有实践显示,把企业工商数据、司法记录、舆情信息融合起来构建的知识图谱,可将关联交易识别率从百分之六十八提升到百分之八十九。不过要留意知识鲜度,尤其是像疫情数据这类时效性强的信息,得建立定期更新机制。
存储与计算技术选型

知识图谱的存储好比选仓库。图数据库(Neo4j)适合复杂关系查询,类似立体车库。RDF存储更适合标准化知识交换,如同集装箱码头。在计算层面,传统查询语言仍占主流。不过到2025年,新兴的图遍历语言在处理深度关联分析时展现出了优势。
某智能汽车项目采用分布式图数据库后,零部件供应链追溯时间大幅缩短。从原来的小时级,缩短至秒级。不过要警惕“技术贪婪症”。在简单场景中,使用关系型数据库效率更高。这就好比社区便利店,没必要建造自动化立体仓库。
典型应用场景剖析
在搜索引擎领域,知识图谱使结果从“网页列表”变为“问题解答”。问“特斯拉创始人有哪些公司”,系统能直接给出结构化答案。在智能客服场景里,基于知识图谱的对话系统能明白“我的手机充不进电”和“充电故障”是同一问题,回答准确率提高55% 。
医疗AI应用愈发振奋人心。有三甲医院把300万份病历建成知识图谱。之后辅助诊断系统对罕见病的识别率提高了3倍。不过要留意伦理边界。患者隐私数据得进行特殊加密处理。这就如同医院档案室得锁起来一样。
未来发展趋势展望

跨模态知识图谱正打破文本限制。到2025年,结合视觉信息的图谱会让AI切实理解“红色警戒游戏封面”与“切尔诺贝利核电站”的联系。动态知识演化技术能使系统自动发觉“某明星解约”事件对品牌口碑的潜在作用。
边缘计算和知识图谱相结合特别值得留意。车载知识图谱可以实时判断“雨量增大 + 能见度降低”的情况,这种情况下需要自动开启雾灯。它的响应速度比云端处理快10倍。不过,随之出现了算力消耗的问题。这就如同给智能手机装上超级计算机那样能耗巨大,所以需要有新的硬件实现突破。
知识图谱与你的专业领域相遇时,你最期望解决哪些当下棘手的难题?欢迎分享你的看法,说不定下一个突破性应用就源于你的灵感。
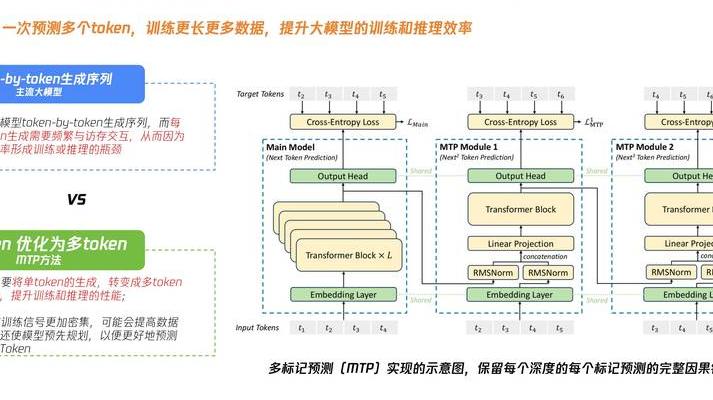



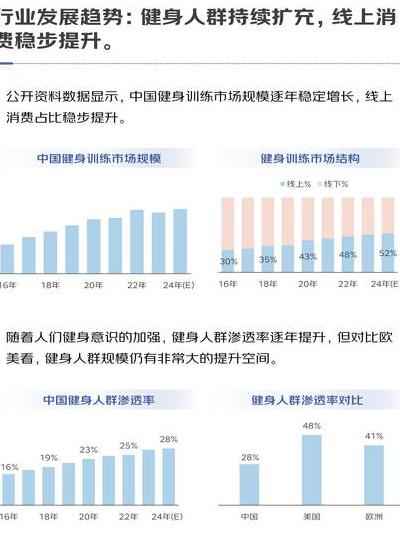




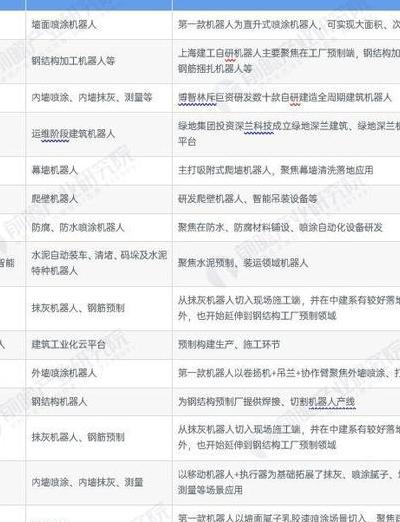
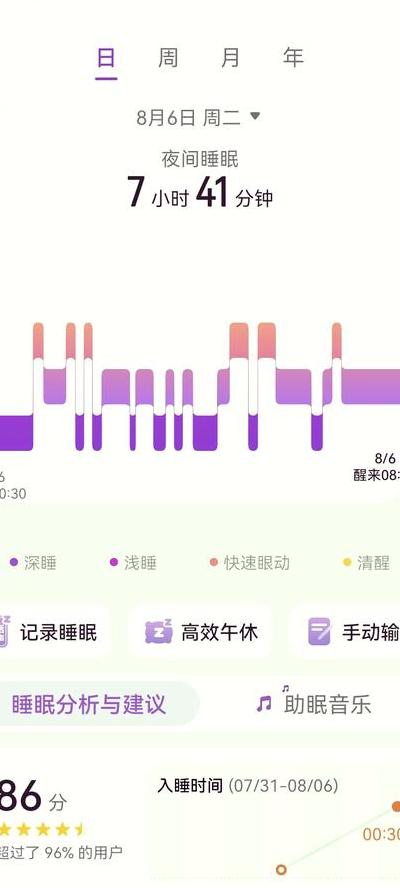


 2025年环保政策持
2025年环保政策持 材料科学创新:纳米
材料科学创新:纳米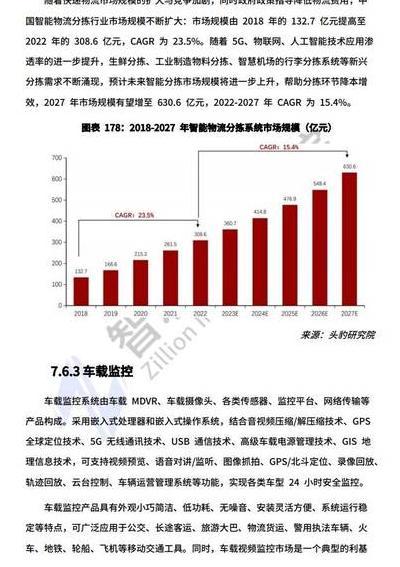 5G技术带来的投资
5G技术带来的投资 山狗A9Pro运动相
山狗A9Pro运动相 从数学神童到区块
从数学神童到区块 2025 科技变革:她
2025 科技变革:她 数字化库房管理变
数字化库房管理变 数字经济时代数字
数字经济时代数字 智能设备维护专业
智能设备维护专业 2025年智能保险服
2025年智能保险服 深入剖析全球医疗
深入剖析全球医疗 2025 年智能保险
2025 年智能保险 全球环保意识下,智
全球环保意识下,智