语音识别技术已深入到我们的生活当中,在智能助手上能见到它,实时翻译里也有它的身影,这项技术正在改变我们与机器交互的方式。本文会对语音识别领域的关键术语进行系统性解释,以此帮助读者理解这项技术的工作原理是什么,发展现状如何,未来趋势怎样。
声学模型
声学模型是语音识别系统里核心组件中的一个,它的职责是把声音信号转变成音素或者子音素单元。现代声学模型一般是基于深度神经网络的,借助大量语音数据来训练,进而学习语音特征跟文本单元之间的映射关系。
在训练的时候,声学模型会去分析语音信号的频谱图,还会分析梅尔频率倒谱系数等声学特征,这些特征可以有效捕捉语音里的关键信息,像音高、音量以及共振峰等,随着技术不断发展,端到端的声学模型正慢慢取代传统的混合模型。
语言模型
语言模型可用来评估文本序列的概率,它能帮助系统在多个可能的识别结果里挑选出最合理的文本。n-gram语言模型是最传统的实现方式,它借助统计大量文本数据中词语的共现频率来预测下一个词。
近年来,基于神经网络的语言模型有了明显进步,这些模型可以捕捉更长的上下文依赖关系,显著提高了语音识别的精准度,特别是在专业领域术语识别上,定制化的语言模型能大幅提升识别的准确率。
唤醒词技术
唤醒词技术能让我们随时凭借语音激活设备,无需进行物理按键操作,这项技术会持续监听环境声音,在检测到特定词汇时,才会启动完整语音识别流程。
唤醒词识别要平衡灵敏度与误触发率,优秀的唤醒系统能在嘈杂环境中准确响应,还能避免被发音相似的词语误触发,一些设备支持自定义唤醒词,可为用户提供更个性化的交互体验。
端点检测

端点检测是一项技术,这项技术能够确定语音开始的位置,也能够确定语音结束的位置,它对实时语音识别来说非常重要。传统方法是基于能量以及过零率等声学特征的,现代系统则更多地使用机器学习模型。
准确进行端点检测,能够显著提升识别效率,还能避免处理无用的静音片段。在连续语音识别里,良好的端点检测可帮助系统正确划分语句边界,进而提高整体识别质量。
说话人识别
说话人识别技术可以区分出不同人的语音特征,进而实现个性化服务。它和语音识别不一样,语音识别关注的是“说了什么”,而说话人识别关注的是“是谁在说”。
这项技术能分成两种应用场景,一种是说话人确认,另一种是说话人辨认。在智能家居里,说话人识别可使设备依照不同家庭成员来调整响应方式,比如播放个人喜好的音乐,或者提供定制的日程提醒。
远场语音识别

远场语音识别应对了设备远距离拾取语音的难题,让智能音箱等产品能在整个房间内正常工作,该技术融合了波束形成、回声消除以及降噪等多种信号处理算法。
在实际应用里,远场识别要处理混响问题,要处理背景噪声问题,还要处理多人同时说话等问题。随着麦克风阵列技术取得进步,现代远场语音识别系统在复杂声学环境中已经能够保持良好表现。
语音识别技术持续取得进步,您最期望哪方面出现创新应用?是对话交互变得更加自然,还是方言识别更加准确?欢迎在评论区分享您的观点,也请为我们的内容点赞给予支持。













 2025年环保政策持
2025年环保政策持 材料科学创新:纳米
材料科学创新:纳米 5G技术带来的投资
5G技术带来的投资 山狗A9Pro运动相
山狗A9Pro运动相 从数学神童到区块
从数学神童到区块 2025 科技变革:她
2025 科技变革:她 数字化库房管理变
数字化库房管理变 数字经济时代数字
数字经济时代数字 2025年智能家电控
2025年智能家电控 2025 年拂晓:智能
2025 年拂晓:智能 2025年智能保险服
2025年智能保险服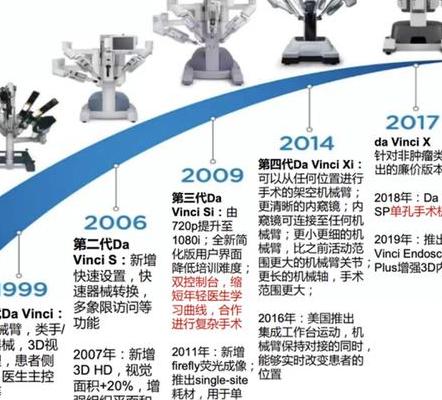 深入剖析全球医疗
深入剖析全球医疗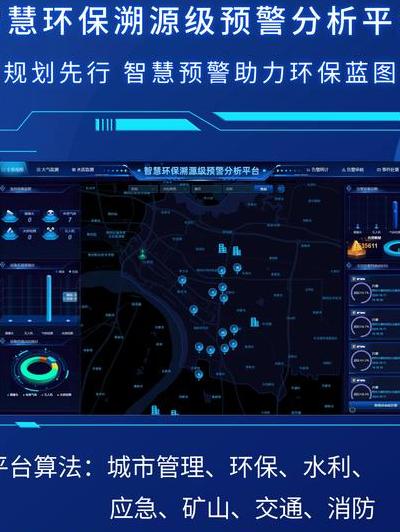 全球环保意识下,智
全球环保意识下,智